
「llms.txtがAI検索時代の新常識らしいけど、結局何を書けばいいの?」「robots.txtやsitemap.xmlとは何が違うの?」「今のうちに導入しておくべき?」と悩んでいませんか。
近年はChatGPTやClaude、Perplexity、Google AI OverviewなどのAI検索サービスが急速に普及し、従来のSEOだけでは十分とは言えない時代になりつつあります。その中で注目されているのが、AIにサイト構造や重要コンテンツを伝えるための「llms.txt」です。しかし、まだ新しい仕様であるため情報が少なく、書き方や設置方法が分からない方も多いでしょう。
この記事では、llms.txtの基本から実際の書き方、コピペできるテンプレート、WordPress・Next.js・Astroでの実装方法までを分かりやすく解説します。この記事を読めば、今日中に自社サイトやブログへllms.txtを導入できるようになります。
「難しそう」と感じるかもしれませんが、ポイントさえ押さえれば作成から公開まで迷わず5分で完了します。競合サイトがまだ対応していない今だからこそ、いち早く導入して社内やクライアントに「次世代SEO対策、完了しました!」と自信を持って報告しましょう!

llms.txtとは?AI検索時代(AIO/GEO)に必須となる新標準仕様
llms.txtの目的とAI検索時代における役割
llms.txt(エルエルエムエス・テキスト)とは、LLM(大規模言語モデル)のクローラーやAI検索エンジンに向けて、Webサイトの概要や重要なコンテンツの構造を効率的に伝えるために設計された新しい標準仕様のテキストファイルです。ファイルは軽量なMarkdown(マークダウン)形式で記述します。
従来のSEO(検索エンジン最適化)では、Googleなどの検索クローラーに「ページを発見してもらい、インデックスさせること」が主目的でした。しかし、AI検索時代(AIO: AI Overview / GEO: Generative Engine Optimization)におけるクローラーの目的は「サイトの文脈(コンテキスト)を正確に理解し、ユーザーへの回答として要約・参照すること」へとシフトしています。
llms.txtの最大の目的は、AIクローラーに対してサイト全体の「正確な地図と要約」を先んじて提示することです。これにより、AIがサイト内の不要な情報を読み込む無駄を省き、自社サイトのコアな強みや正確な一次情報を優先的に学習・参照させることが可能になります。

従来のrobots.txtやsitemap.xmlとの明確な違いと併用メリット
Webサイトの巡回を制御するファイルには、すでにrobots.txtやsitemap.xmlが存在します。これらとllms.txtは競合するものではなく、明確に役割が異なるため併用が必須となります。
それぞれの役割と違いは以下の通りです。
| ファイル名 | 主な対象 | 記述形式 | クローラーへの役割・命令 |
|---|---|---|---|
| robots.txt | 全ての検索・AIクローラー | プレーンテキスト | 「立ち入り禁止(クロール拒否)」の制御。アクセス制限が主。 |
| sitemap.xml | 従来の検索エンジン | XML形式 | 「存在する全URL」の網羅的なリスト。インデックス促進が主。 |
| llms.txt | LLM・AI検索クローラー | Markdown形式 | 「サイトの概要・重要文脈」の要約。文脈理解の支援が主。 |
併用するメリット
AIクローラーのアクセス自体を制御したい場合はrobots.txtを使用し、アクセスしてきたAIクローラーに対して「まずここを読んでサイトの概要を掴んでくれ」とナビゲートするためにllms.txtを機能させます。
これらを併用することで、AIクローラーの巡回効率を最大化しつつ、生成AIの回答ソースに選ばれやすいサイト構造へと最適化できます。
ChatGPT・Claude・Perplexity・Google AI Overviewとllms.txtの関係
現在、ChatGPT(OpenAI)、Claude(Anthropic)、Perplexity、そしてGoogleのAI Overview(AIO)などの主要なAIサービスやAI検索エンジンは、回答の信頼性を担保するために、リアルタイムでWebサイトをクロール・参照(リファレンス)しています。
従来のAIクローラー(GPTBotやClaudeBotなど)は、サイト内のHTMLを泥臭くスクレイピングし、テキストを解析していました。しかし、これには以下の問題点がありました。
- ナビゲーションや広告などのノイズが多く、重要なコンテンツを誤解する
- LLMのトークン(文字数)制限により、長いドキュメントの全容を把握しきれない
- 重要な情報が階層の奥深くにあり、クロールされずに無視される
llms.txtをルートディレクトリに設置しておくことで、これらのAIクローラーはサイト巡回の最初にこのファイルを読み込みます。
ファイル内に構造化された「サイトの概要」と「主要ドキュメントへのMarkdownリンク」があるため、AIは瞬時にサイトの文脈を把握できます。結果として、PerplexityやSearchGPT、Google AI Overviewにおいて、回答の根拠となる「参照元リンク(ソース)」としてあなたのサイトが選ばれる確率を高めることができます。AI検索に無視されないための強力なアドバンテージとなるのが、このllms.txtです。
※2026年の段階ではAIクローラー全体の解析効率が上がることで間接的な好影響は期待できますが、「AIOへの即効性のある特効薬」とまでは行きません。
あなたのサイトのURL、そろそろスリムにしませんか?llms.txtの書き方と基本構成
llms.txtの基本構成 – サイト名・概要・リンク一覧の書き方
llms.txtは、AIがパース(解析)しやすいように構造化されたシンプルなテキストファイルです。基本構成は主に以下の3つの要素で成り立っています。
- サイト名(H1見出し):サイトの正式名称を記述します。
- サイトの概要(プレーンテキスト):サイト全体が何について書かれているか、どのようなサービス・メディアなのかをLLM向けに短く要約します。
- リンク一覧(H2見出し + 箇条書きリンク):AIに優先的に読み込ませたい主要ページや、詳細な情報を網羅した
llms-full.txt(後述)へのリンクを記述します。
構成の最大の特徴は、「人間ではなく、LLM(AIクローラー)が読むことを前提に最適化されている」点です。回りくどい表現は避け、主語と目的語を明確にした論理的な文章で記述するのが鉄則です。
Markdown形式での正しい記述方法とUTF-8・プレーンテキストの注意点
llms.txtを記述する際は、以下の技術的なルールと注意点を必ず厳守してください。正しくフォーマットされていない場合、AIクローラーにファイルを無視されたり、エラーの原因になったりします。
- 中身はMarkdown、拡張子は「.txt」
ファイル名は必ずllms.txtとし、中身はMarkdown(マークダウン)の構文ルールに従って記述します。HTMLタグ(<h1>など)は使用せず、#や##の見出し記号を使用してください。 - 文字コードは必ず「UTF-8」
日本語環境で作成する際、Shift-JISやEUC-JPなどで保存してしまうと、海外製のAIクローラー(GPTBotやClaudeBotなど)が文字化けを起こし、内容を正しく理解できなくなります。保存時は必ずUTF-8(BOMなし)を指定してください。 - 装飾や複雑なレイアウトは不要
太字()や斜体(*)などの装飾、複雑なテーブル(表)などは、LLMのトークン(解析コスト)を無駄に消費するだけでなく、パースエラーの引き金になります。見出し、標準的な段落、箇条書き、およびプレーンなURLリンクのみで構成するシンプルな構造がベストです。
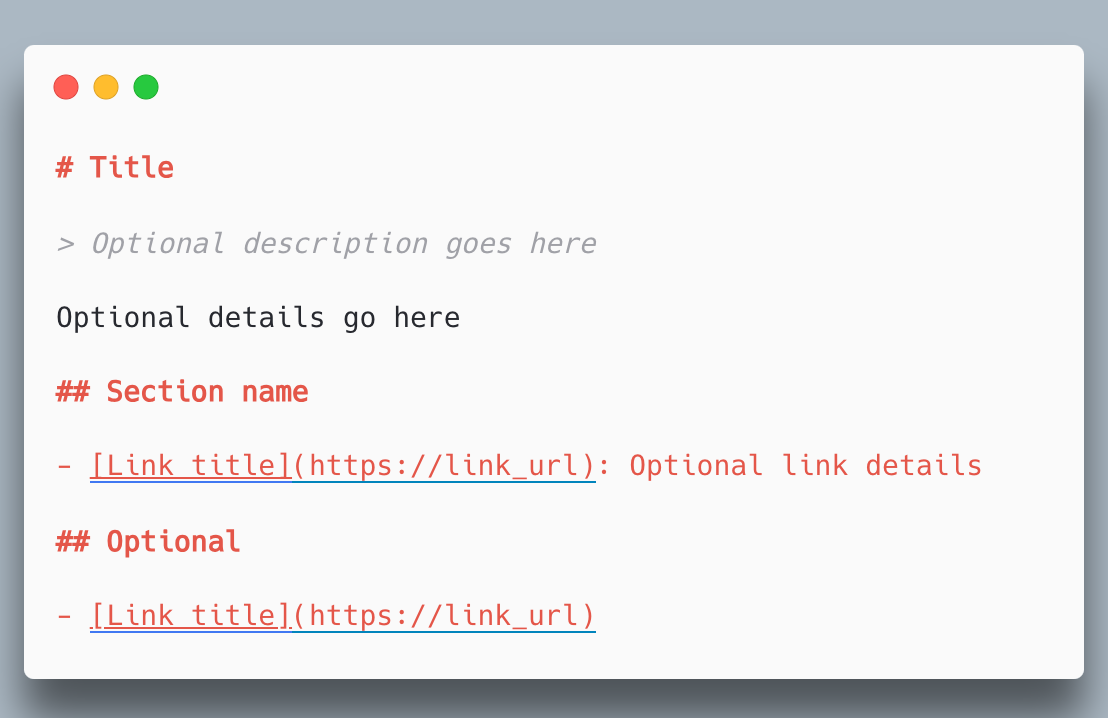
コピペOK|最低限これだけで使えるllms.txtテンプレート例
以下は、自社サイトやオウンドメディア、ブログなどにそのまま導入できる、標準的なllms.txtのテンプレートです。コードブロックの内容をコピーし、ターゲットサイトの情報に書き換えるだけで、5分で有効なファイルを作成できます。
# サイト名(例:TechWeb Production)
> サイト全体の短いキャッチコピーや、LLMに対する主要な補足情報(オプショナル)
ここにサイト全体の概要を簡潔に記述します(2〜3文程度)。
例:当サイトは、フロントエンド開発、テクニカルSEO、およびWebデザインに関する実践的なノウハウを発信する技術ブログです。エンジニアやWebディレクター向けに、パフォーマンス最適化や最新のAI検索対応(AIO/GEO)に関する信頼性の高い一次情報を提供しています。
## 重要なリソース
AIクローラーに優先的に巡回・学習させたい主要なコンテンツや、ドキュメントのインデックスへのリンクをここに記述します。
- [公式ドキュメント / サービス概要](<https://example.com/about>) - 弊社の主要サービスとエンジニア向け機能の概要
- [テクニカルSEOカテゴリ](<https://example.com/blog/seo>) - 最新の検索エンジン最適化に関するコア記事一覧
- [開発ロードマップ](<https://example.com/roadmap>) - 2026年現在のプロダクト開発状況と今後の予定
## 詳細情報
より詳細な情報や、全ページの完全なドキュメントリストは以下のファイルを参照してください。
- [llms-full.txt](<https://example.com/llms-full.txt>) - サイト内のすべての公開ページと詳細な要約を含むフルバージョン
記述時のライティングのコツ
概要文(Description)を記述する際は、「主語(当サイトは〜)」を明確にし、「誰に向けて」「どんな価値(情報)を」提供しているかを具体的に言語化してください。AIはこの記述を元にサイトのトピック(専門分野)をマッピングするため、キーワード(例:「Next.js」「テクニカルSEO」など)を自然に含めることが重要です。
llms.txtの設置場所・ファイル名・公開方法
llms.txtはどこに置く?ルートディレクトリ直下の配置ルール
llms.txtの配置場所には厳格なルールがあります。それは、Webサイトの「ルートディレクトリ直下」に配置することです。
AIクローラー(GPTBotやPerplexityBotなど)は、特定のWebサイトを訪問した際、あらかじめ決められた固定のパス(URL)を自動的に直撃してファイルを探索する仕様(プロトコル)になっています。そのため、サブディレクトリ内や任意のフォルダに配置しても、AIに認識されません。
必ず以下のURLでアクセスできる場所にアップロードしてください。
正しい配置(ルート直下): <https://example.com/llms.txt>
誤った配置(カテゴリ下): <https://example.com/assets/llms.txt>
誤った配置(ブログ下) : <https://example.com/blog/llms.txt>サブドメイン(例:blog.example.comやdocs.example.com)を運用している場合は、それぞれのサブドメインのルート直下(https://blog.example.com/llms.txt)に個別に設置する必要があります。
ファイル名・URL・文字コード・サイズ制限の基本知識
確実にAIにファイルを認識させ、パース(解析)エラーを防ぐために、以下の基本仕様をサーバー設定やファイル作成時に必ず満たしているか確認してください。
- ファイル名(すべて小文字)
ファイル名は必ずすべて小文字のllms.txtとします。Linuxサーバーなどの環境では大文字・小文字が厳密に区別されるため、LLMs.txtやLLMS.TXTとするとクローラーが404エラー(検出不能)を返します。 - 文字コードと改行コード
文字コードはUTF-8(BOMなし)を使用します。改行コードは、サーバー環境に合わせてLF(推奨)またはCRLFとしてください。 - ファイルサイズ制限とトークン管理
通常版のllms.txtは、AIクローラーが「瞬時にサイトの全体像を把握するためのファイル」です。そのため、ファイルサイズは数KB〜数十KB程度に抑えるのが理想です。文字数が多すぎると、LLMが1回で処理できるコンテキストウィンドウ(トークン上限)を圧迫し、重要な末尾の情報が切り捨てられるリスクがあります。詳細な全ページリストは、後述するllms-full.txtに記述して切り分けます。
robots.txt・sitemap.xml・schema.orgとの併用方法
llms.txtを公開する際は、既存のSEO資産(robots.txt、sitemap.xml、schema.org)と組み合わせることで、従来の検索エンジンとAI検索エンジンの両方に対して完璧な最適化(GEO/SEOのハイブリッド対応)が実現します。
1. robots.txt での記述(任意)
AIクローラーにファイルの存在を明示的に知らせるため、robots.txt の末尾に llms.txt のURLを記載しておくアプローチが標準化されつつあります。
※2026年現在、「llms:」というディレクティブは、GoogleやIETF(インターネット技術タスクフォース)によって公式に標準化された仕様ではありません。記述すること自体にエラー等の害はありませんが、標準的なクローラーがこの記述を確実にパースする保証はないため、ルート直下への確実な配置(/llms.txt)による自動検出を主軸と考えるべきです。
User-agent: *
Disallow: /wp-admin/
Sitemap: <https://example.com/sitemap.xml>
llms: <https://example.com/llms.txt>2. sitemap.xml との棲み分け
sitemap.xmlは機械的な全URLのインデックス登録用としてそのまま残し、llms.txtには「AIに特に理解してほしいコアページ、概念図、重要カテゴリ」のみを人間が読めるMarkdown形式で抽出して記載します。
3. schema.org(構造化データ)との併用
schema.orgは、個々のページ内のデータ(著者、価格、評価、FAQなど)を検索エンジンにセマンティックに伝える仕組みです。一方でllms.txtは「サイト全体の文脈や要約」をLLMに伝える役割を持ちます。
- schema.org = ページ単位の「属性・ファクト」を伝える(点の設定)
- llms.txt = サイト全体の「意味・文脈・構造」を伝える(線の設定)

これら3つのファイルを正しく連携させることで、Googleの通常クローラー、Google AI Overview(AIO)、そしてOpenAIなどの外部LLMのすべてに対して、隙のないサイトインフラを構築できます。

llms-full.txtとの違いと使い分け・どこまで詳細に書くべきか?
llms-full.txtとは?通常版llms.txtとの役割の違い
llms.txtの仕様には、メインとなる llms.txt のほかに、llms-full.txt というもう一つのファイルが定義されています。これらは、AIクローラーに対する「情報の粒度(深さ)」によって明確に役割が分けられています。
- llms.txt(要約)
サイトの全体像、主要なカテゴリ、最も重要な数ページのリンクのみを掲載した「インデックス」です。AIクローラーが最初の数秒でサイトの文脈を誤解なく理解できるように、意図的に情報を絞り込んで記述します。 - llms-full.txt(詳細ドキュメント)
サイト内のすべての公開ページ、詳細な技術ドキュメント、あるいは各ページの具体的な内容(コンテンツそのもの)を網羅した「完全版」です。AIがサイトの情報を深く学習したり、具体的な回答の裏付けとなる一次情報を一括で取得したりする際に参照されます。
イメージとしては、llms.txt が本の「表紙・目次・ビジネス概要」であり、llms-full.txt が「本編の全章・詳細データ」にあたります。
▼llms.txtの仕様を提唱しているプロジェクトサイト
llms-full.txtに含めるべき全ページURLとファイルサイズ・文字数の制限目安
llms-full.txt は詳細に書くべきファイルですが、何でも無制限に記述してよいわけではありません。AIが効率的にパース(解析)できるように、以下の基準と目安を意識して構造化します。
含めるべき情報
- サイト内のすべての主要な公開ページのURL
- 各ページが「何について書かれているか」を1〜2文で説明した要約(Description)
- ドキュメントサイトや技術ブログの場合、主要記事のMarkdownテキスト(本文そのもの)を結合して配置するケースもあります。
ファイルサイズ・文字数の制限目安
LLMのコンテキストウィンドウ(一度に処理できるトークン数)は年々劇的に拡大していますが、クローラーの処理効率や通信コストの観点から、以下の制限を目安にしてください。
- ファイルサイズ:最大 5MB〜10MB 程度(テキストファイルとしては非常に大容量ですが、大規模なドキュメントサイトでない限りは数百KBに収めるのが理想です)。
- 階層構造の維持:URLの単なる羅列ではなく、以下のように
llms.txtと同様のMarkdownの箇条書き(H2やH3でのセクション分け)を用いて、構造的に記述します。
# フルリソースインデックス(llms-full.txtの例)
## 開発ガイド
- [インストール方法](<https://example.com/docs/install>) - 環境構築と初期設定の完全な手順
- [認証機能の実装](<https://example.com/docs/auth>) - JWTを用いたセキュアなログインの実装方法
## APIリファレンス
- [ユーザーAPI](<https://example.com/api/users>) - ユーザー情報取得・更新エンドポイントの仕様
- [決済API](<https://example.com/api/checkout>) - Stripe連携の決済処理フローとパラメータ
llms.txtとllms-full.txtは両方設置するべき?
結論から言うと、「サイトの規模と業態によって両方設置すべきか判断する」のが最も効率的です。社内への提案やリソース配分の基準として、以下の判断ツリーを活用してください。
【パターンA】llms.txt のみで十分なケース(1ファイルで完結)
- 対象:個人ブログ、小規模なコーポレートサイト、シンプルなLP(ランディングページ)。
- 理由:総ページ数が数十ページ程度であれば、わざわざファイルを分けずとも、
llms.txtの1ファイルの中にサイト概要と主要リンクをすべて収めることができるためです。管理コストを最小限に抑えられます。
【パターンB】両方(llms.txt と llms-full.txt)設置すべきケース
- 対象:大規模な技術ブログ、公式ドキュメントサイト(SaaSのヘルプセンターなど)、オウンドメディア、ECサイト。
- 理由:ページ数が数百〜数千に及ぶ場合、1つのファイルにまとめると
llms.txtが巨大化し、AIクローラーが最初の「概要理解」でパンク(トークン切れ)してしまいます。そのため、まずは軽量なllms.txtでサイトの骨組みを理解させ、必要に応じてllms-full.txtへディープクロール(深層巡回)させるという、二段階のナビゲーションが必須となります。
両方設置する場合は、必ず llms.txt の一番下のセクションに llms-full.txt へのリンクを明記 してください。これにより、AIクローラーが迷わず次の詳細情報へアクセスできるようになります。
WordPress・Next.js・Astroでの実装方法
WordPressでllms.txtを生成・設置する方法
WordPressで運用しているサイトにllms.txtを実装する場合、サイトの更新頻度や管理方針に合わせて「静的配置」と「動的生成」の2つのアプローチがあります。
1. 最も簡単な「静的配置」の手順
サイトの構造が大きく変わらない場合は、手動で作成した llms.txt をサーバーに直接アップロードするのが最も確実です。
- ローカル環境でテキストエディタを開き、UTF-8形式で
llms.txtを作成・記述する。 - FTPツール(FileZilla等)またはレンタルサーバーのファイルマネージャーを使用する。
- WordPressがインストールされているルートディレクトリ(
wp-config.phpやindex.phpが存在する階層)に直接アップロードする。
2. functions.php を使った「動的生成(バーチャル配置)」の例
固定ページや新着記事の情報を動的に反映させたい場合は、テーマの functions.php に以下のコードを追加することで、物理的なファイルを置かずに https://example.com/llms.txt にアクセスした際の内容をプログラム側から出力(ルーティング)できます。
function generate_virtual_llms_txt(){
if (isset($_SERVER['REQUEST_URI']) && $_SERVER['REQUEST_URI'] === '/llms.txt') {
header('Content-Type: text/plain; charset=utf-8');
echo "# " . get_bloginfo('name') . "\n\n";
echo "## 概要\n";
echo get_bloginfo('description') . "に関する情報を発信する技術メディアです。\n\n";
echo "## 主要リソース\n";
echo "- [" . get_bloginfo('name') . " ホーム](" . home_url() . ") - 最新記事一覧\n";
// 特定の固定ページやカテゴリを動的に出力するロジックをここに追記可能
exit;
}
}
add_action('init', 'generate_virtual_llms_txt');
Next.js・Astro・静的サイトジェネレーターでの実装例
モダンなフロントエンドフレームワークや静的サイトジェネレーター(SSG)を利用している場合、public フォルダへの配置、またはエンドポイント(Route Handlers / API Routes)を活用した自動生成が可能です。
1. Next.js(App Router)での実装例
静的ファイルとして配置する場合は、public/llms.txt にファイルを設置するだけで公開可能です。
もし、Headless CMS(MicroCMSやContentfulなど)からデータを取得して動的に llms.txt を生成したい場合は、Route Handler(app/llms.txt/route.ts)を作成します。
// app/llms.txt/route.ts
import { NextResponse } from 'next/server';
export async function GET(){
// 必要に応じて外部CMSからカテゴリや主要ドキュメントの一覧を取得
// const data = await fetchCMSData();
const content = `# 開発者向けテックブログ (Next.jsビルド)
当サイトは、フロントエンド開発、Next.js、TypeScriptに特化した技術解説サイトです。
## 主要リソース
- [ホーム](<https://example.com/>) - 最新のフロントエンド技術記事
- [AIO/GEO対策ガイド](<https://example.com/posts/aio-geo>) - AI検索最適化の解説
`;
return new NextResponse(content, {
status: 200,
headers: {
'Content-Type': 'text/plain; charset=utf-8',
},
});
}
2. Astroでの実装例
Astroの場合も、同様に public/llms.txt に配置するだけで静的ファイルとしてルーティングされます。
ビルド時に動的にコンテンツを生成したい場合は、src/pages/llms.txt.ts を作成して静的エンドポイントとして出力します。
// src/pages/llms.txt.ts
import type { APIRoute } from 'astro';
export const GET: APIRoute = async () => {
const markdownContent = `# Astroテックブログ
Astroフレームワークを用いた高速なWebサイト制作とパフォーマンス最適化のノウハウをまとめています。
## 重要リンク
- [Astro導入実績](<https://example.com/cases>) - 自社制作の事例紹介
`;
return new Response(markdownContent, {
status: 200,
headers: {
'Content-Type': 'text/plain; charset=utf-8'
}
});
};
自動生成ツールを使った更新・メンテナンスの自動化
大規模なWebサイトや、日々コンテンツが追加されるメディア・ECサイトにおいて、llms.txt や llms-full.txt を手動で更新し続けるのは現実的ではありません。AIクローラーに常に最新の正しい情報を伝えるために、メンテナンスを自動化する仕組みを導入しましょう。
1. CI/CDパイプライン(GitHub Actions)への組み込み
Next.jsやAstroなどのジャムスタック(Jamstack)構成であれば、ビルドスクリプト(Node.jsなど)を1本作成し、sitemap.xml やローカルのMarkdownファイル群、またはCMSのAPIから全URLとメタデータをパースして、自動で llms-full.txt を生成するステップをビルドプロセスに挟むアプローチが最も効率的です。
2. 既存のサイトマップ(sitemap.xml)からのコンバート
sitemap.xml のURLリストをインプットとし、各ページの <url> 要素とタイトル情報(または簡易ディスクリプション)を機械的にMarkdownの箇条書きに一括変換するスクリプトを定期実行(cron等)させることで、完全に手放しで llms-full.txt の同期を維持することができます。
URLが変更されたり古いページが削除されたりした際、llms.txt の更新が漏れているとAIクローラーが404エラーに直面し、サイトの評価を下げる原因(ハルシネーションの誘発など)になります。「URL構造に変更があったら、llms.txtも自動追従する」設計を開発初期に組み込んでおくことが、効率的な運用の鍵となります。
よくある質問(FAQ)
-
llms.txtの中で、特定のAIクローラーの拒否や、特定のコンテンツの除外設定(robots.txtのDisallowのような記述)は可能ですか? -
いいえ、
llms.txtでクローラーの拒否(アクセス制御)を行うことはできません。llms.txtは、アクセスを許可しているAIクローラーに対して「サイトの文脈を正しく理解してもらうためのガイド(推奨情報)」を提供するファイルです。特定のLLM(GPTBotやClaudeBotなど)の巡回を拒否したい、あるいは会員限定ページなどインデックスされたくないコンテンツがある場合は、従来通りrobots.txtでの制御、または対象ページのメタタグ(noindexやnoimageindex)での拒否設定が必須となります。AIに読み込ませたくないコンテンツは、単に
llms.txtやllms-full.txtにリンクや概要を掲載しない(ノイズを削ぎ落とす)という形でコントロールしてください。
-
日本語主体のWebサイトの場合、概要文は日本語だけで書いても海外製AI(ChatGPTやClaudeなど)に正しく理解されますか?
-
基本的には日本語のみの記述でも問題なく理解されますが、海外トラフィックやグローバルAIを意識するなら英語との併記(バイリンガル)が推奨されます。
OpenAIやAnthropic、Googleなどの最新LLMは極めて高度な多言語処理能力を持っているため、
llms.txtに記述された日本語を正確に解釈し、自社サイトの文脈をマッピングできます。ただし、海外のテックニュースからの流入を狙いたい場合や、開発者向けドキュメント、グローバル展開を視野に入れているSaaSなどの場合は、英語で記述するか、以下のようにセクションを分けて併記(バイリンガル対応)にするアプローチが有効です。
# サイト名(TechWeb Production) 当サイトは、テクニカルSEOとフロントエンド開発のノウハウを発信するメディアです。 (This site is a technical media outlet providing insights into technical SEO and front-end development.)
-
作成した
llms.txtに構文エラーがないかをチェックできる公式のバリデーター(検証ツール)はありますか? -
2026年現在、W3Cなどの公的機関による「公式バリデーター」は存在しません。しかし、LLM自体を用いたローカルテストが非常に有効です。
記述したMarkdownがAIに正しくパース(解析)されるか不安な場合は、以下のステップでローカルテストを行ってください。
- エディタのプレビュー確認
VS CodeやNeoVimなどのMarkdownプレビュー機能を使用し、見出し(#)の階層構造や、リンク([テキスト](URL))の構文が視覚的に崩れていないか確認する。 - AI(ChatGPTやClaude)に直接読ませる
作成したllms.txtの中身を丸ごとコピーし、ChatGPTやClaudeに「以下のllms.txtの構文にパースエラーがないかチェックし、このサイトの概要と重要ページを3行で要約してください」とプロンプトを投げます。AIが意図通りにサイトの構造を理解し、正しい要約を出力できれば、実運用上でのテストは合格と判断して問題ありません。
- エディタのプレビュー確認
-
llms.txtを導入・運用する上で、どのようなリスクや注意点がありますか? -
最大のリスクは「機密情報の誤掲載」と「リンク切れ(情報の形骸化)」の2点です。
- 機密情報の漏洩リスク
llms.txtは公開サーバーのルート直下に配置されるため、誰でも(競合他社でも)ブラウザからアクセスして閲覧できます。一般公開前のステージング環境のURLや、社内向けの未公開ドキュメントの要約などを誤って記述しないよう、掲載情報の公開範囲は厳格に管理してください。 - ハルシネーション(誤情報)の誘発リスク
サイトのリニューアルやURL変更を行った際、llms.txt内の記述を古いまま放置してしまうと、AIクローラーが404エラーに直面します。これにより、AIが古いコンテキストを引きずったまま回答を出力し、AI検索上での自社サイトの評価低下やハルシネーションを誘発する原因になります。URL構造の変更時には、必ずllms.txtも同時に追従・更新する運用フローを構築してください。
- 機密情報の漏洩リスク
まとめ
AI検索(AIO/GEO)の台頭によって、Webサイトに求められるSEOの形は「インデックスさせること」から「文脈を正しく理解させること」へと確実に変化しています。その新しい常識として登場したのが、今回解説した llms.txt です。
これまで通り robots.txt や sitemap.xml で検索エンジンへの交通整理をしつつ、llms.txt を使ってAIクローラーに「自社サイトの取扱説明書」を渡してあげる。このハイブリッドな対応こそが、SearchGPTやPerplexity、Google AI Overviewといった次世代の検索エンジンに無視されないための最も確実なステップになります。
ここで、この記事の特に重要な部分を振り返ってみましょう。
llms.txt の導入は、記述ルールさえ押さえてしまえばテンプレートを使って5分で完了する手軽な施策です。しかし、競合サイトがまだ手を付けていない今だからこそ、先んじて実装する価値は極めて高いと言えます。
「AIクローラーへの最適化なんて、まだ早いのでは?」と思うかもしれません。ですが、海外のテックトレンドはすでにこの仕様を標準として動き始めています。ぜひ今回のテンプレートを活用して、今すぐあなたのサイトにも llms.txt を組み込んでみてください。
あわせて読みたい


